谷歌发布1800元月的AI订阅,还把通用AI塞进了生态每个角落

软件硬件双管齐下,定义「下一代 AI 产品」怎么做。
作者|张勇毅
首先是一个冷知识:ChatGPT 中的「T」代表「Transformer」,这个概念是谷歌的一群工程师在 2017 年提出的,并发表在一篇现在已成经典的论文《Attention Is All You Need》中。
这个小细节,很大程度上能说明谷歌在 AI 领域并不是一个花架子团队,而是由一群 AI 产品业内经验最丰富的老兵组成的团队,从 Gemini 2.5 发布之后,Google 在 AI 领域的优势已经颇有点「渐入佳境」的感觉:基础模型能力的大幅提升,加上 Gemini 在谷歌软件生态内的逐渐深入,让全球数以十亿计的用户都在这个过程中,逐渐被「转化」成谷歌 AI 产品的用户。
如何「转化普通用户变成 AI 产品用户」,是这个时代几乎所有 2C AI 产品都需要回答的问题,显而易见,在这个问题上,Google 已经凭借着巨大的存量用户优势,甩开了所有竞争对手——但谷歌同样需要奔跑不停,才能在 Perplexity、OpenAI 以及微软等强大竞争对手的围剿中,留住用户的心。
Google 显然最清楚在端侧 AI 爆发的时代,谷歌的实际优势在哪里,用户同样知道谷歌知道他们想要哪些 AI 能力,出现在自己最常用的日常应用中。

这就是今年谷歌 I/O 2025 大家的共识,Google 也确实在主题演讲中,几乎全程都在介绍谷歌在这些领域中的潜力,以及向世界展示,AI 能给这些用户原本已经熟悉的使用体验带来哪些改变。
01
Google 搜索引擎 AI Mode 深入
作为目前巨头中 AI 落地成效最显著的选手,Google 毫不掩饰自己在 AI 产品商业化用户规模上的领先,上来就展示了大量 AI 能力在谷歌产品中的实际应用成果。
Google CEO 桑达尔 - 皮查伊 介绍,基于 Gemini 能力的 AI 总结功能现在已覆盖全球超过 15 亿用户,AI 总结功能在全球的调用次数增长已经超过 10%,而且这种增长还在持续。多模态识别能力的谷歌 Lens 现在同样已经有超过 15 亿的月活用户。

桑达尔 - 皮查伊将其称为「搜索引擎过去十年内最成功的革命」| 图片来源:极客公园
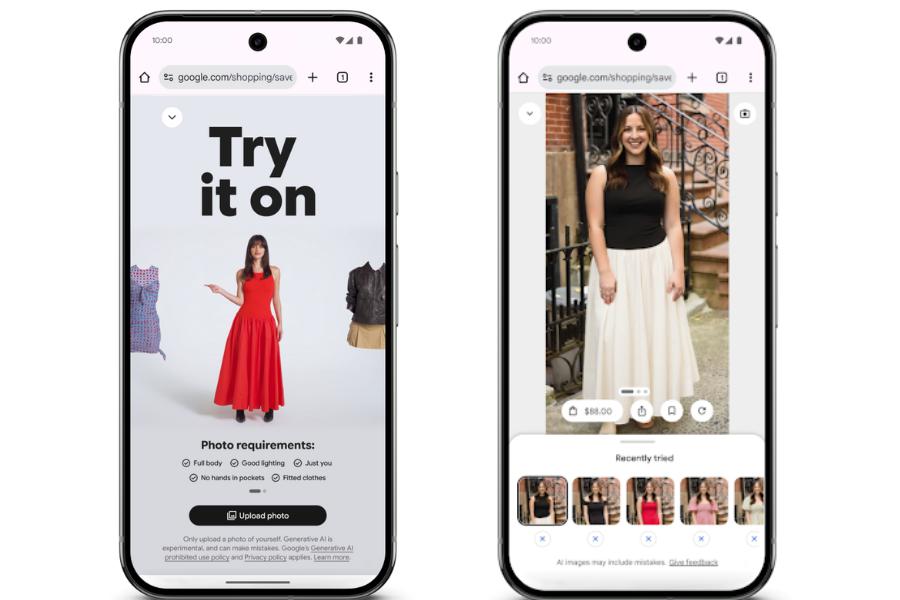
但 AI 显然不只是能在搜索引擎上起到作用,比如谷歌同时就宣布了新的「虚拟试穿」功能,谷歌会要求你提供一张全身照片,通过大模型「理解人体和服装的细微差别,不同材料在不同身体上折叠、拉伸和垂坠。然后使用这张照片,生成你穿着你正在选购的衣服的图像。
一直传闻中的谷歌想要借助 Chrome 入局 AI 浏览器,本次 IO 中也终于崭露头角,除了 Chrome 浏览器本身更深度的整合 Gemini 接口、识别网页内容以外,谷歌还为搜索引擎添加了全新的「AI 模式」。这个模式把类似 Gemini 或 ChatGPT 的聊天机器人功能直接带入了用户的网页搜索体验。你可以用它来找链接,但也能更快地获取信息、追问问题,让 Gemini 以平时在普通网页上找不到的方式来整合信息。
谷歌搜索的负责人甚至放出豪言:如果你想知道互联网上最重要的搜索引擎未来会变成什么样,那你就去点开「AI 模式」看看。
「AI 模式」同时也支持深度研究功能,会自动将用户的提示词转化为海量的搜索,并自动查找和整合信息,同时在这个模式下,AI 搜索还可以访问你之前的搜索记录,你也可以手动开启权限,让它可以访问你的电子邮件,以便 AI 能更了解「你是谁」以及你关心什么。
把所有这些功能加起来,你就会得到一个更加灵活和个性化的 AI 搜索,无论是针对用户本身还是当前的具体查询,显然都能根据用户信息给出更加精准的回答。
Gemini 2.5 家族也同时加入了支持深度思考的版本 —— Gemini 2.5 Pro Deep Think,在 2025 年美国数学奥林匹克竞赛 ( USAMO ) 中取得了 40.4% 的高分,要知道这可是最难的数学基准测试之一,比之前的 2.5 Pro 版本足足提升了 10 多个百分点。同时在 LiveCodeBench 竞赛级编程难题中,它的得分更是高达 80.4%。同时,在多模态推理 MMMU 测试中,也取得了 84.0% 的成绩。

Gemini Live 的摄像头共享功能于去年在谷歌 I/O 大会上首次亮相,当时它的名字还叫 Project Astra,随后作为 Gemini Live 在 Android 上正式推出。它允许谷歌 Gemini「看到」您摄像头中的一切,因此您可以就周围的世界进行持续对话——例如,根据冰箱中的食材询问食谱建议。
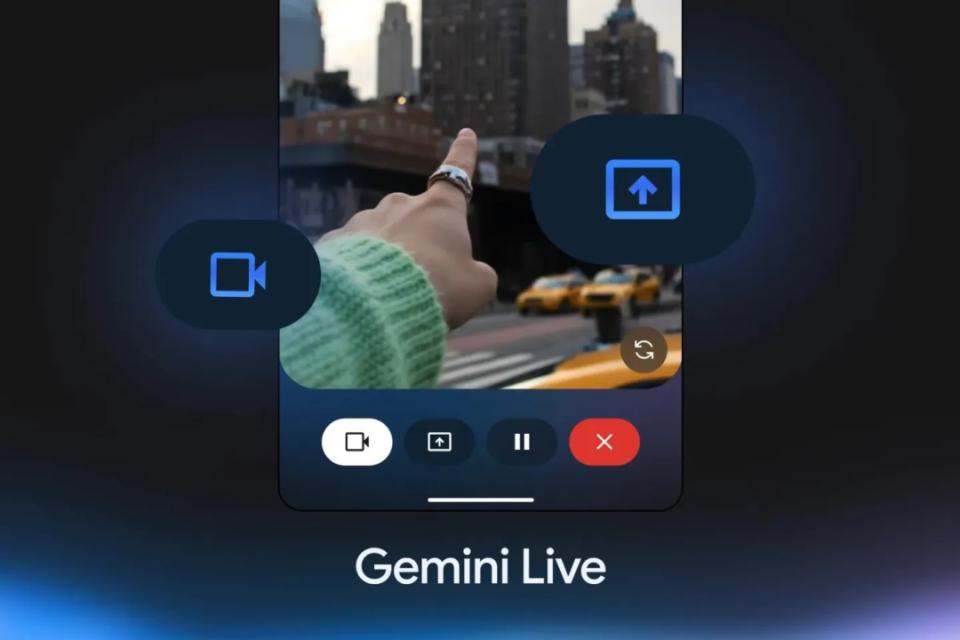
随着谷歌在用户场景中逐渐深入,现在这一功能被直接引入搜索的 AI 模式中,通过点击「Live」图标,用户将能够与搜索共享他们的摄像头画面,并直接询问眼前的事物,例如自行车应该如何组装。并且可以自动根据上下文对你们的情况进行同步更新回答。

在现场的演示中,最令笔者印象深刻的新功能,是其新获得的主动性。可以根据它观察到的事件选择何时开口,像一个真人一样,对你的操作进行建议,例如在用户做作业时进行观察,它可能会注意到您犯了一个错误,并直接指出用户哪里错了,而不是反过来等着用户要求 AI 去执行任务。
据 DeepMind CEO Demis Hassabis 表示,教 AI 自主行动一直是计划的一部分。这些「察言观色」的技巧,是人类相对擅长但难以量化或研究的事情。
02
Android XR
明眼人看到这里已经能反应过来了:比起手机摄像头,这个如此深入现实世界的多模态 AI 功能,似乎更适合的载体是在眼镜上。
Google 显然同样想到了这一点,随即趁热打铁,宣布了 Android XR 的新进展,同时在现场展示了谷歌 XR 眼镜的原型机。
在演示中,Google 强调它们是使用 Gemini 的「最佳硬件」:Google 的、 展示的原型眼镜搭载有相机,麦克风和扬声器,Gemini 可以调用这些硬件,帮用户理解周围的世界。同时在显示屏上显示类似地图导航等更多信息。

目前,谷歌正通过与三星、XREAL 的合作,来研发首批搭载 Android XR 操作系统的眼镜硬件。谷歌 XR 副总裁 Shahram Izadi 表示,第一款硬件设备是三星的 Project Moohan,但那是一款更接近 Apple Vision Pro 的 XR 头显。第二款 Project Aura 属于 XREAL。定位是一款 AR 眼镜。

除了三星、XREAL 这样的硬件厂商,Google 显然也是从 Meta Ray-Ban 的大获成功中吸取到了经验,同时也宣布了与包括 Gentle Monster 在内的两家时尚眼镜巨头合作,一同将 AI 眼镜打造的更加时尚。
03
AI 创作全家桶
除了直接面向最多普通用户的 Gemini,Google 同时还针对创作者的一系列 AI 创作工具,进行了更新换代 —— 其中不仅有直接与 Sora 竞争的 Veo3、图像生成工具 image4,Lyria 2 音乐生成模型,还有全新视频创作工具 FLOW。

Veo 3 相比前代,最大的升级是它可以生成包含音效、背景噪音,甚至对话的视频。
谷歌现场演示了一段 CGI 级别的生成动画,其中动物在森林里说话。声音和视频完美同步:有声音的视频显然大大提升了 AI 生成视频的实用性。谷歌 DeepMind 首席执行官 Demis Hassabis 也表示:「我们正在走出视频生成的‘无声时代’。」
Google 同步宣布了「大杯」和「超大杯」订阅服务,AI Pro 与 AI Ultra,其中顶配的谷歌 AI Ultra 要价每月 249 美元,但同时也确实提供了物超所值的服务 —— 例如几乎无限制的各项服务使用额度,以及 30TB 的谷歌 Cloud 云端存储容量。
AI Ultra 计划允许用户试用 Gemini 2.5 Pro 全新的增强推理模式 Deep Think,据谷歌介绍,该模式专为「高度复杂」的数学和编程问题设计。它还提供 Chrome 中 Gemini 的早期访问权限,允许订阅者直接在浏览器中使用 AI 完成任务和总结信息。

除了这些之外,订阅用户还可以试用谷歌的 AI Agent 原型 —— Project Mariner,可以同时自动化多达 10 项任务,例如查找信息、预订和购买产品。

通过将 Gemini 能力深度融入搜索引擎、Chrome 浏览器、虚拟试穿、乃至全新的 Android XR 生态和 AI 眼镜,Google 不仅在提升现有产品的用户体验,同时也是在潜移默化地定义「下一代 AI 产品」怎么做。
显然,在端侧 AI 产品如何做这件事上,Google I/O 展示出的「软件硬件双管齐下」,已经足以让谷歌再次成为 AI 产品生态中最让人忌惮的选手。
* 头图来源:极客公园