GPT-4o连验证码都解不了??SOTA模型成功率仅40%
当前最强多模态 Agent 连验证码都解不了?
MetaAgentX 团队推出首个专注于 " 多模态交互智能体 × CAPTCHA(人机验证)问题 " 的开放式研究平台——Open CaptchaWorld。
该平台专门用于测试 Agent 解验证码的能力。

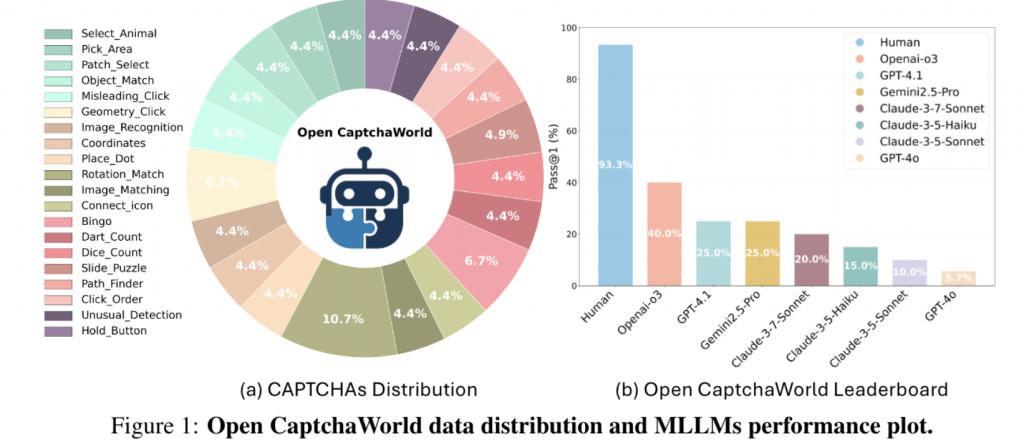
实测结果显示:人类平均成功率达93.3%,SOTA 多模态模型平均仅5%-40%不等。
连GPT-4o都被难住了。
验证码是现阶段 Agent 部署的一大瓶颈
在真实网页场景中部署多模态 Agent,你是否也被人机验证(CAPTCHA)卡住过?
项目团队发现,不少大型 Benchmarks(包括 AgentBench、VisualWebArena 等)在构建过程中都刻意跳过了含验证码的网页,仿佛这道拦路虎根本不存在。
但现实很骨感:验证码从不是 " 特例 ",而是任何实际任务中不可回避的存在,尤其在电商、登录、票务等高价值网页中更是常见。
于是,Open CaptchaWorld 这个测试平台以及 Benchmark 应运而生:一个针对多模态大模型 Agent 的 CAPTCHA 解题平台与评估基准——专为视觉 - 语言 - 动作交互任务设计。
无论是 OpenAI 的 o3、Anthropic 的 Claude ‑ 3.7-sonnet、还是 Gemini ‑ 2.5-pro,这些最新的多模态大模型 Agent 尽管在静态感知任务(如图文问答、UI 理解)中表现出色,但在真实交互环境中常常卡在了 CAPTCHA 环节:
WebAgent 在执行 end-to-end 任务时,常因验证码而被 " 卡死 ";
AgentBench、VisualWebArena 等主流评估集普遍过滤掉含 CAPTCHA 的网页;
过去的验证码研究(如 reCAPTCHA、DeepCAPTCHA)更聚焦静态识别,对交互、多步规划与状态跟踪能力评估严重不足。
为了系统性地评估 Agent 在验证码中的真实表现,研究团队设计了一个全新的开放基准与平台——Open CaptchaWorld。
这个平台不仅包含最新的现代验证码而且类型丰富(20 种),全部在真实 Web 浏览环境中进行操作,真正复现 Agent 实际遇到的挑战:
" 解图 + 理解规则 + 计划操作 + 逐步交互 " = Agent 能力的真实考验。

Open CaptchaWorld 平台具体特点
1、 大规模、多样性以及覆盖全面:研究团队创作了商用的最新的20 类现代验证码,累计 225 个样例;类型涵盖点击顺序、滑块对齐、图像选择、数字计数、拖拽匹配等。
2、 交互真实:所有验证码均部署在网页环境中,Agent 必须通过观察截图、点击、拖动等方式完成操作,模拟真实用户交互流程。
3、 提出新评估指标CAPTCHA Reasoning Depth:用于量化一个验证码背后需要多少步 " 视觉理解 + 认知计划 + 动作控制 " 的过程;是对传统 " 静态图像分类 " 评价方式的重要补充,更贴近 Agent 真实解题难度。
4、 对比分析详尽:对 OpenAI-o3、GPT-4o、Claude-3.7、Gemini2.5-Pro 等模型进行系统评估;人类解题成功率高达 93.3%,最强模型 OpenAI-o3 仅为 40.0%;并从策略偏差、视觉错误、执行失败等维度剖析失败原因。
数据构造方法
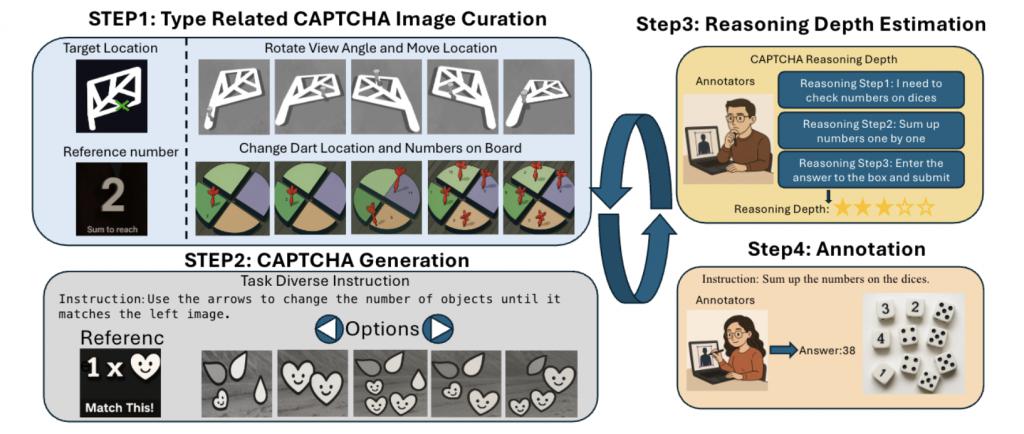
Open CaptchaWorld 的数据集构建遵循四阶段流程,旨在生成多样化、高质量、可交互的 CAPTCHA 样本,用于评估多模态智能体在真实网页场景下的表现。
第一步:图像素材构建(Type Related CAPTCHA Image Curation)
根据每类 CAPTCHA 的设计需求,由人类设计师或者 GPT-4o 生成具有变化性的图像素材。
包括目标位置、观察角度、对象排布、数字与元素分布等多种视觉因素的系统调整,确保每类任务在结构上具有足够的多样性与泛化性。
第二步:验证码生成(CAPTCHA Generation)
围绕构造好的图像素材,为每个实例配套生成自然语言指令,任务描述由人类设计或由大模型辅助生成,确保语言表达清晰,易于 Agent 理解。
指令内容涵盖点击、滑动、拖动、计数、比对等典型交互操作,结合网页前端组件实现真实交互逻辑。
第三步:推理深度估计(Reasoning Depth Estimation)
为精确刻画每道 CAPTCHA 的解题复杂度,引入 "CAPTCHA Reasoning Depth" 指标。
该指标通过人工注释者对解题过程的逐步分解,记录人类在完成任务时涉及的视觉识别、逻辑判断、记忆操作与交互控制等原子推理步骤,并据此评估任务的综合认知深度。
第四步:标准注释生成(Annotation)
最终由标注人员确认每个 CAPTCHA 实例的标准答案,包括操作路径、点击位置或数值输入结果。
所有任务均保证为人类易解(成功率高),同时具备统一的判定逻辑和网页反馈接口,为模型训练与评估提供稳定可靠的标签支撑。
多模态 Agent 在验证码面前 " 过度思考、频繁失败 "
该团队发现,多数先进 Agent 在 CAPTCHA 面前显得手足无措,不仅成功率低,而且解题行为远不如人类高效。
例如在 " 序列点击 " 任务中:人类通常只需识别图案 → 记住顺序 → 一次性点击完成;
模型(如 OpenAI-o3)往往会把操作细化为十余步,比如 " 记住第一个图标 "、" 确认当前状态 "、" 点击后等待反馈 " …… 这种 " 过度分解任务 " 的现象。不仅拖慢操作流程,还增加了出错概率。
这类现象反映出当前 Agent 在高交互、高动态场景下的显著劣势:缺乏人类式的抽象、泛化与控制能力。

除此之外研究团队还展示了当前主流多模态大模型 Agent 在 Open CaptchaWorld 上的成本 - 性能权衡关系。
从下图所示,横轴为评估成本(以对数刻度表示),纵轴为 CAPTCHA 解题任务中的 Pass@1 成功率(百分比)。每个点代表一个具体模型的运行结果。

从图中可以看出,OpenAI-o3 虽然在成功率方面显著领先(达 40.0%),但同时也是成本最高的模型,显示出较强的能力但较差的性价比。
而 Gemini2.5-Pro 和 GPT-4.1 等模型在保持相对较高成功率(约 25%)的同时,成本控制更为合理,展现出较好的 " 单位预算表现 "。
相比之下,Claude-3.5-Sonnet、GPT-4o 与 OpenAI-o1 等模型尽管评估开销中等或偏高,但解题成功率较低,显示出在当前 CAPTCHA 场景下的适配能力仍较弱。
DeepSeek-V3 和 Claude-3.5-Haiku 成本较低,成功率保持在 15%~20% 区间,体现出更优的成本效率平衡,适合作为轻量级基线。
总体来看,该图揭示了多模态 Agent 在真实交互任务中并不总是 " 越贵越强 ",也突出了 Open CaptchaWorld 平台在分析 Agent 实用性、可部署性方面的重要价值。
未来的模型设计应更加关注效率与性能之间的协同优化。
Open CaptchaWorld 平台为 Agent 开发者、基准设计者提供了新的思路。
也揭示了——
当前 Agent 的真实 " 短板 " ——长序列任务动态交互和规划交互能力;
现有 Benchmark 评估的盲区——大量省略了真实部署中不可或缺的 " 人机验证 " 环节;
新模型设计方向——如何提升 Agent 在现实网页任务中的自动化与鲁棒性。
Agent 时代下的新型 Captcha 设计——目前的 Captcha 迟早会被 Agent 能力增长而攻破,我们也需要实时更新设计新的 Captcha 来顺应技术的发展。
Open CaptchaWorld 的提出旨在鼓励研究者在训练和评估 Agent 时,不再回避 CAPTCHA 问题,而是勇敢面对它,因为在现实世界中,如果连验证码都通过不了,这个 Agent 就无法落地。