Qwen3家族训练秘籍公开:思考/非思考融进一个模型,大模型蒸馏带动小模型
Qwen3 技术报告新鲜出炉,8 款模型背后的关键技术被揭晓!
采用了双模式架构,一个模型同时支持推理和非推理任务,根据需要自动切换。
训练和微调过程采取分段式策略,逐步构建模型能力。
采取了 " 大带小 " 的模式,从大号模型中蒸馏数据训练小号模型。

有已经读完报告的网友,还发现了其中的更多亮点。
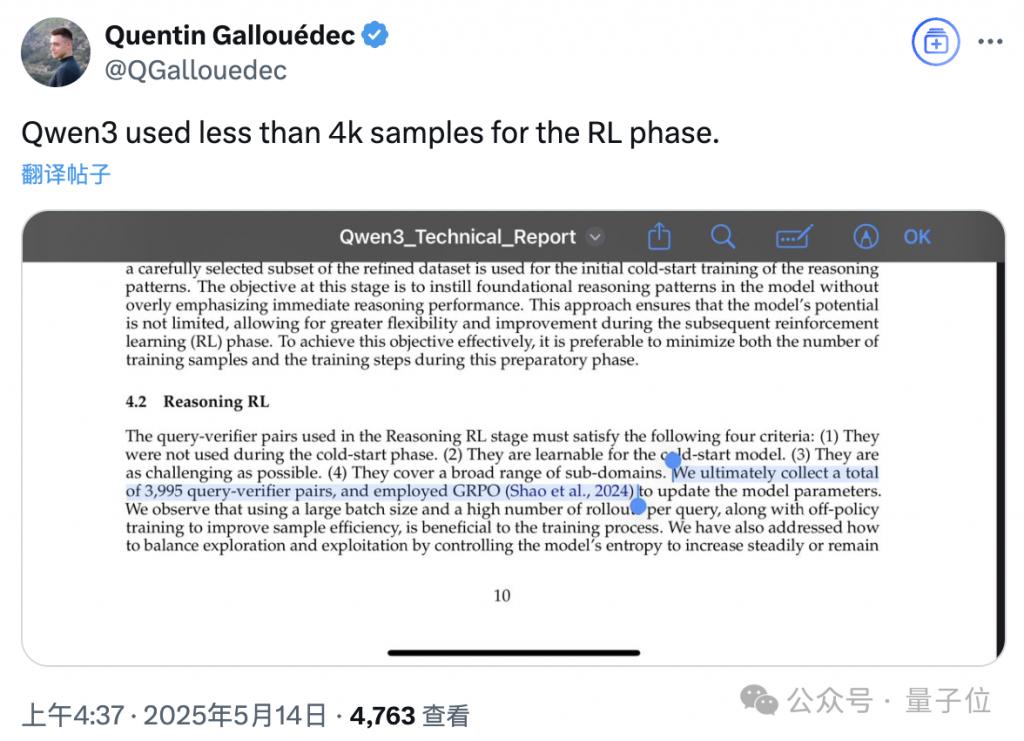
比如这位 Hugging Face 研究员感叹,Qwen3 在 RL 阶段的样本量,竟然不到 4k。
思考 / 非思考,一个模型搞定
Qwen3 系列包括 6 个密集模型,参数量分别为 0.6B、1.7B、4B、8B、14B 和 32B;以及 2 个 MoE 模型,总参数量分别为 30B 和 235B,激活参数量对应为 3B 和 22B。
密集模型的架构与 Qwen2.5 相似,但移除了 Qwen2 中使用的 QKV 偏置,并在注意力机制中引入了 QK-Norm,以确保 Qwen3 的稳定训练。
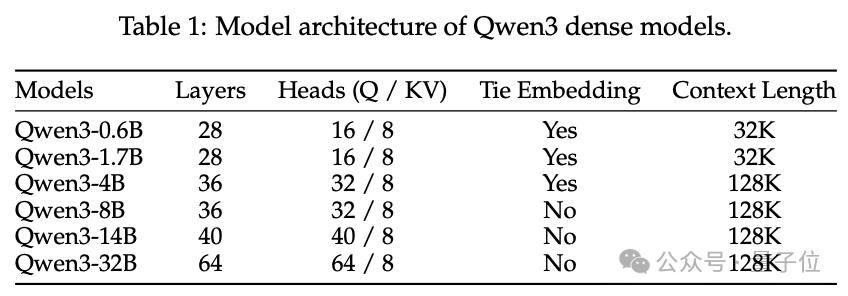
与 Qwen2.5-MoE 不同,Qwen3-MoE 设计不包含共享专家,另外 Qwen3 采用了全批次负载均衡损失来促进专家专业化。

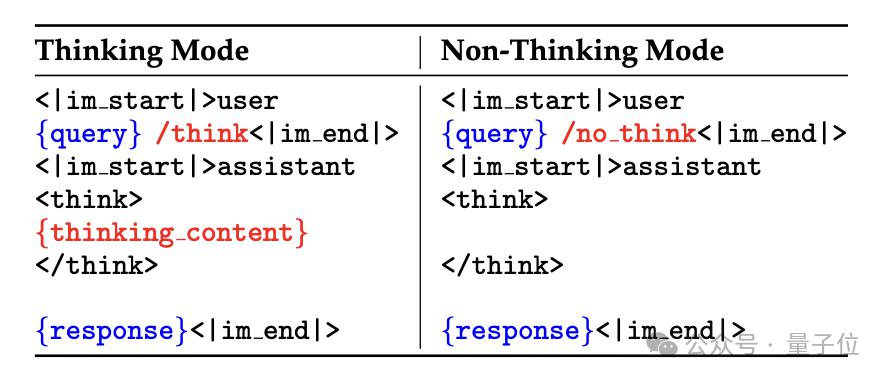
Qwen3 的一个核心创新就是其双重工作模式,也就是思考模式和非思考模式的融合,两种模式分别对应了复杂推理任务和快速应答任务的需求。
为了灵活地在两种模式间切换,Qwen3 引入了 thinking budget(思考预算)的概念。
Thinking budget 本质上是一个决定 thinking mode 下计算资源投入的参数,它的大小与输入问题的复杂程度成正相关。
当接收到输入后,模型会评估其复杂程度,动态分配 thinking budget。
简单问题会被分配较少的 thinking budget,使得模型倾向于快速给出答案;复杂问题则会分配较高的 thinking budget,模型会投入更多算力深入思考后再给出答案。
Qwen3 这样训练
预训练环节,Qwen3 采用了三阶段策略,逐步构建和强化模型的语言理解和生成能力。
第一阶段的目的是让模型掌握语言和通用基本知识,这部分的训练在通用语料上进行,采用了 4096 个 token 的序列长度。
第二阶段侧重于增强模型的推理能力。此阶段采用了更高质量的语料,主要来自于 STEM、编程、推理等领域。
通过在这些语料上的训练,模型的逻辑分析、因果推理等能力得到了显著提升。此阶段的序列长度仍为 4096 个 token,但学习率衰减速度加快。
第三阶段则专注于长文本能力,使用了研究团队专门收集的高质量长文档语料,并将训练序列长度扩展到了 32768 个 token。
通过在这些超长文本上的训练,模型学会了处理复杂的长距离依赖关系,掌握了跨段落、跨文档的信息整合技能。

后训练同样采用了分段式的方法,一共可以分为四个阶段。
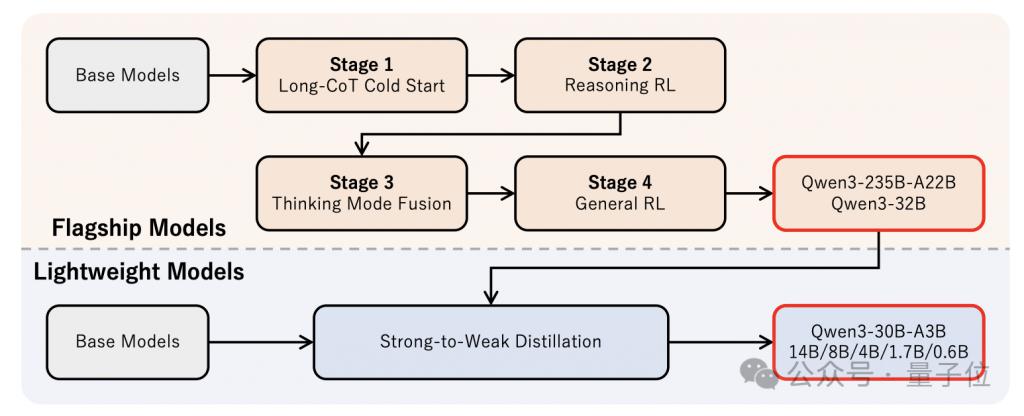
第一阶段称为长思维链冷启动,目标是为模型在数学和编程领域的推理任务建立初始的解题能力。
Qwen 团队构建了一个包含大量高质量数学和编程问题的数据集,并为每个问题标注了详细的解题步骤,然后使用这些标注数据对模型进行监督微调,使其掌握解题的关键技能和常见思路。
具体来说,他们通过 Qwen2.5-72B 对问题进行筛选,然后使用 QwQ-32B 模型自动生成初步的解题步骤,这当中,人类专家对这些自动生成的解题步骤进行核对和修正,确保其准确性和可读性。
这个阶段的训练样本数量和训练步数都被控制在一个较小的规模,目的是让模型掌握基本的解题能力,而不是过度专门化。

第二阶段则是推理强化学习,在第一阶段的基础上进一步引入了强化学习,以优化模型的解题策略。
他们从第一阶段的数据集中筛选出了 3995 个问题,这些问题需要覆盖一定领域、具备一定难度,但可被模型学习。
这一阶段当中,会通过 GRPO 对模型参数进行更新。

第三阶段思维模式融合,顾名思义,目的是将思考和非思考两种模式融合进同一个模型,这一过程使用了同时包含思考和非思考内容的 SFT 数据集。
对于思考类型的样本,Qwen 团队沿用了前两个阶段的数据生成方法;对于非思考类型的样本,则是广泛收集了一些开放域对话数据,并针对性地生成了一些问候语、指令等样本。
此外,团队还设计了一种聊天模板,在输入侧用一些特殊标记来区分思考和非思考模式。
通过在这个混合数据集上进行继续预训练,并融入人类反馈,模型学会了根据输入信号灵活切换两种模式,形成了一个无缝集成的双模态系统。

最后一个阶段是通用强化学习,目的是进一步增强模型在多种场景下的能力和稳定性。
该阶段中,Qwen 团队构建了一个覆盖广泛任务的强化学习环境,包括问答、写作、代码生成、数学推理等 20 多个种类的任务。每个任务都设计了独特的评分标准。
并且,这些特别针对指令遵循、格式遵循、偏好遵循等能力的提升。

除了这样的训练模式之外,Qwen3 家族还采用了 " 大带小 " 的数据蒸馏模式。
蒸馏分为 Off-policy 蒸馏和 On-policy 蒸馏两个主要阶段。
类比人类学习的话,第一个阶段像是背书,第二个阶段则是刷题并自己根据答案订正。

在 Off-policy 蒸馏阶段,首先使用教师模型(MoE 模型使用 235B 蒸馏 30B,密集模型使用 32B 蒸馏其他)在大规模的数据集上生成大量高质量的输出。
然后,这些数据作为监督信号,对学生模型进行训练,使之尽可能地模仿教师模型的输出分布。
在这个阶段,教师模型使用的是思考和非思考模式的混合输出,这使得学生模型也能够同时学习到应对两种模式的能力。
在 On-policy 蒸馏阶段,研究团队采用了一种更加动态和交互式的学习方式。
这个阶段首先让学生模型在实际任务中自主生成一系列输出,然后将这些输出与教师模型在相同任务上的输出进行比对。
学生模型的优化目标是最小化其输出分布与教师模型输出分布之间的差异。
通过这种持续的自我生成和比对过程,学生模型可以在实践中不断修正和完善其知识体系,使其输出分布逐步逼近教师模型。
Qwen 版 DeepResearch 上线
除了发布 Qwen3 的技术报告,Qwen Chat 还全量上线了深度研究功能,此前该功能进行了分阶段测试。
按官方介绍,只要描述问题,然后回答模型给出的细化提问,等过一杯咖啡的时间,Qwen 就能整理出一份研究报告。
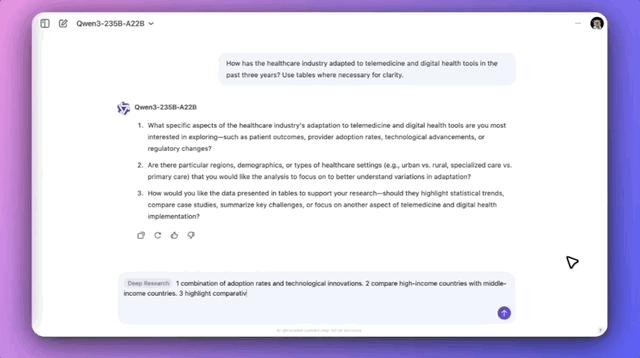
官方案例中,Qwen 研究了这样的一个问题:
医疗保健行业在过去三年中如何适应远程医疗和数字健康工具?必要时使用表格让表达更加清晰。
可以看到,在明确具体需求之后,Qwen 规划了方案,然后分成子问题进行检索、总结,研究过程用时约 8 分半,最终生成了带有表格的报告,并自动导出 pdf。
感兴趣的话不妨体验一下 ~
报告地址:
https://github.com/QwenLM/Qwen3/blob/main/Qwen3_Technical_Report.pdf
Qwen Chat:
https://chat.qwen.ai
— 完 —
量子位 AI 主题策划正在征集中!欢迎参与专题365 行 AI 落地方案,一千零一个 AI 应用,或与我们分享你在寻找的 AI 产品,或发现的AI 新动向。
也欢迎你加入量子位每日 AI 交流群,一起来畅聊 AI 吧~
一键关注 点亮星标
科技前沿进展每日见
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!