推理“刹不住车”?新框架让DeepSeek-R1们告别过度思考,已开源
DeepSeek-R1、OpenAI o1 等推理模型大放异彩。但随着能力增强,一个副作用越来越明显——
它们开始想太多了。
从奥数题到程序逻辑,能解的题越来越多、推理链条越来越长。
也就是说,模型在完成推理任务时,常常出现过度思考:
步骤繁冗:明明两步能解完,非要绕七八步,搞得逻辑链又长又乱;
表述拖沓:简单结论非要用复杂语言兜圈子,说了一堆才到点子上;
输出冗长:生成了大量无效 tokens,既浪费算力,又拖慢推理速度。
这不光影响效率,更可能导致错误——在长链式思考中,每一步的小误差都会累积放大,最后可能想着想着就跑偏了。

于是,一个关键问题摆在了现实面前:
如何让模型既然会思考推理,也懂得 " 适可而止 ",知道什么时候该停下来?
针对于此,来自浙江大学、天津大学和 MSRA 的研究团队提出了一个新方法,Self-Braking Tuning(SBT)。
它是一种轻量级、通用的调优机制,可无缝集成到现有大模型中。其主要目的是让模型不再一味求 " 多想 ",而是在最短路径上到达正确答案。
其核心设计包括刹车信号机制、多任务微调,且无需外部模块或改动推理流程。
其中,刹车信号机制是在训练阶段引入一类特殊的信号,指示 " 当前信息已经足够完成任务 ",模型据此学习何时应终止推理。
多任务微调则指挥模型同时学习如何解题 & 何时停步,兼顾准确性与效率。
总结成一句话,SBT 就像在大模型头脑里装了个 " 限速器 ",让它不再无休止地输出,更聪明,也更节能。

让模型知道自己 " 是否想太多 "
SBT 框架的核心目标,是让模型具备自我判断是否 " 想得太多 " 的能力,能够在无需外部干预的情况下,适时终止推理过程。

它的特别之处在于,不依赖外部规则或指令,而是从模型内部出发,重塑模型对自身思考状态的理解与掌控力。
简单来说,就是让模型像人一样,在觉得 " 想得差不多了 " 时,能够自然地停下来,而不是无休止地继续推理。
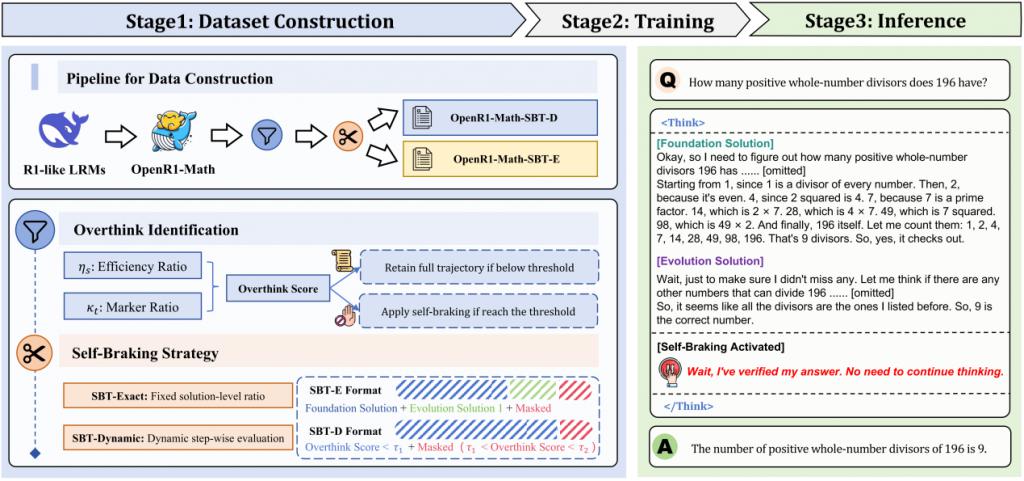
构建过度推理识别指标体系
为了更有效地识别推理过程中可能出现的冗余部分,研究团队构建了一套参考标准答案的评估体系。
他们将推理划分为两个主要阶段:基础方案(Foundation Solution)和进化方案(Evolution Solution)。
前者是模型在初步理解问题后给出的第一轮解答,而后者则是大模型后续对这一初始方案的进一步思考、补充和验证。
基于此,团队提出了两个核心指标:推理效率比和过度推理标记比。
推理效率比衡量表示的是模型在达到第一个正确答案所需的推理步骤与整个推理过程总步骤的比例。
比例越接近 1,表示模型的推理效率越高,过度推理的可能性越低。
而过度推理标记比则通过分析推理过程中的语言模式,识别与过度推理行为相关的特定词汇,如 "Wait""But""However" 等,来量化过度推理的严重程度。
这两种指标相互补充,从结构和语言两个维度全面评估推理过程中的冗余程度。
创新性数据构建策略
研究团队基于上述指标体系,开发了 Self-Braking Tuning Exact(SBT-E)和 Self-Braking Tuning Dynamic(SBT-D)两种互补的数据构建策略。
SBT-E 采用了一种统一的截断策略,对每条推理路径进行结构化处理。
在存在过度推理的案例中,保留模型生成的基础解决方案以及一个进化方案,并补充一小段被掩码的后续内容。
这样的设计有助于模型在训练时明确区分哪些推理是必要的,哪些则是多余的,从而逐步学会控制推理的深度,避免无效延展。
SBT-D 则采用逐步适应的策略,根据不同问题的特点动态调整推理长度。
从完整保留基础解决方案开始,逐步添加后续推理步骤,并在每一步重新计算过度推理分数。当分数超过预设的阈值时,停止添加推理步骤,并将超出部分进行掩码处理。
这种方法使得模型能够在不同复杂度的问题上自适应地终止推理,避免过度推理的发生。
自我调节制动策略
除了数据构建策略外,研究团队还引入了自我调节制动策略,进一步增强模型对推理过程的自我控制能力。
在 SBT-E 和 SBT-D 构建的数据样本里,研究团队对推理过程的后期冗余部分进行了掩码处理。
这就像给模型的推理之路设置关卡,挡住那些非必要的重复思考。
模型能看见这些被掩码的内容,但在训练时,这些部分不会计入损失函数,仿佛是 " 只展示不考核 "。
通过这种方式,模型逐渐学会聚焦关键推理步骤,不再深陷无意义的冗余思考,从而提升推理效率。
除了对冗余推理部分进行掩码处理,SBT 框架还引入了自然语言提示机制,作为引导模型停步的辅助方式。
这些提示以简洁的语言表达模型当前的判断,例如:"Wait, my answer is too verbose. Let me answer it more concisely"。
借助语言模型对语义的理解能力,这种方式能够在推理过程中起到提醒作用,帮助模型识别信息已足够、无需继续展开,从而减少无谓生成,提升整体推理的效率与简洁性。
实现 " 少思考但不失准确 " 的效果
在数学推理基准测试(AIME、AMC、MATH500、GSM8K)上,研究团队对 SBT 框架进行了广泛的实验评估。
从实验结果来看,SBT 框架在多个数学推理数据集上展现出了显著的性能提升,尤其是在推理效率方面,取得了前所未有的进展。
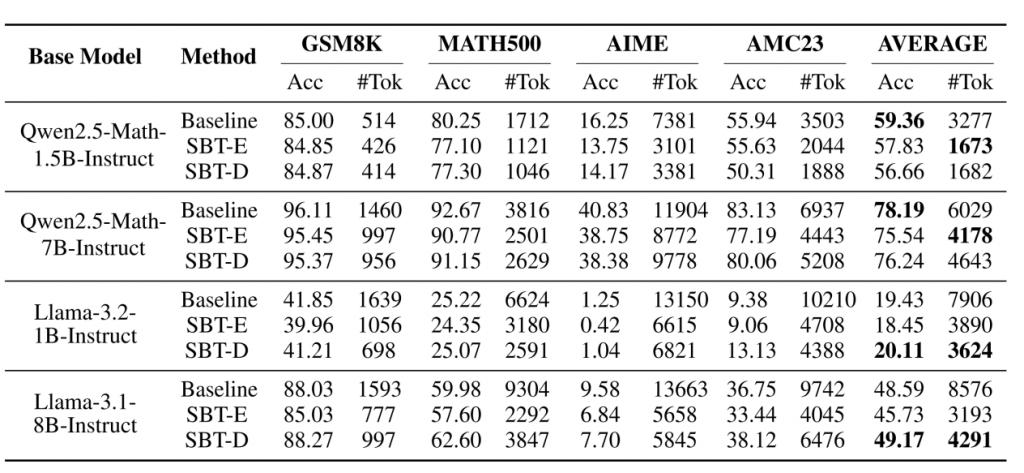
相比于传统的完整推理过程,SBT 通过识别并主动规避冗余推理步骤,实现了 " 少思考但不失准确 " 的效果。
以 Llama-3.1-8B-Instruct 模型为例,应用 SBT-E 策略后,模型在推理过程中生成的 token 数量减少了 62.8%,但最终的准确率仍稳定维持在 94.1%。
更为重要的是,这一方法在多个模型架构和规模下均表现出高度的稳定性和通用性,充分证明了其方法论的鲁棒性和推广价值。
它不仅证明了大量推理内容在实际任务中是冗余的,而且表明这些冗余部分的剔除不会损害模型对复杂数学问题的理解与解答能力。
论文地址:
https://arxiv.org/pdf/2505.14604
项目主页:
https://ZJU-REAL.github.io/SBT
GitHub:
https://github.com/ZJU-REAL/Self-Braking-Tuning
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
点亮星标
科技前沿进展每日见