视频语义编码:现状、挑战与展望
【6G内生智能理论与关键技术】
2025年第1期专题 - 14
视频语义编码:现状、挑战与展望
令潇越,鲁国,张文军
【摘 要】语义通信作为一种新兴的通信范式,通过直接传递信息的语义内涵提升通信效率,满足多样化的应用需求,也被称为面向任务的通信。视频语义编码作为其重要组成部分,逐渐成为研究热点。基于此,回顾了视频语义编码领域的研究进展,将现有方法分为两类:深度学习驱动的编码框架和传统与智能协同编码框架。首先,介绍了深度学习驱动的编码框架,包括特征流编码、视频流编码和人机协同编码三种技术路线。这些方法依赖于全神经网络,通过端到端优化提升性能,但其高计算资源需求限制了实际部署。接着,探讨了传统与智能协同编码框架。该框架结合传统编码与人工智能技术的优势,提升了系统的性能与灵活性。最后,总结了视频语义编码面临的挑战,并展望了未来的发展方向。
【关键词】语义通信;视频编码;机器视觉任务
中图分类号:TN919.81 文献标志码:A
文章编号:1006-1010(2025)01-0109-05
引用格式:令潇越,鲁国,张文军. 视频语义编码:现状、挑战与展望[J]. 移动通信, 2025,49(1): 109-113.
LING Xiaoyue, LU Guo, ZHANG Wenjun. Video Semantic Coding: Current Status, Challenges, and Future Directions[J]. Mobile Communications, 2025,49(1): 109-113.
0 引言
近年来,语义通信逐渐成为通信领域的研究热点,被视为第六代(6G, Sixth Generation)无线网络所面临的重要机遇之一。与传统通信侧重于比特层面的精确重建不同,语义通信的核心目标是传递信息的语义内涵。具体而言,发送端需要有效提取原始信息的语义特征并进行编码,接收端则需准确解码和推理,从而提升通信效率和任务执行的准确性。基于这一特性,语义通信也被称为面向任务的通信[1]。随着人工智能(AI, Artificial Intelligence),特别是深度学习技术的飞速发展,语义通信的实现得到了强有力的技术支持。例如,文献[2-3]、[4-5]、[6-9]以及[10-11]分别探讨了针对文本、语音、图像和视频模态的端到端语义通信系统设计,展现了语义通信在各类应用中的广阔前景。
文献[12]指出,语义通信与传统通信的一个最大区别在于信源编码阶段。在传统通信中,信源编码侧重于精确恢复原始信号,尽可能减少信号级失真;而语义通信则更加关注从原始信号中提取和编码有意义的语义特征,以满足下游任务的需求。与此同时,考虑到视频数据在互联网流量中占据主导地位[13],且随着6G技术的发展,机器间通信的需求激增,尤其是在自动驾驶、安防监控等应用场景中,对视频数据的处理效率和智能化处理能力提出了更高的要求。因此,视频语义编码作为语义通信的重要组成部分,逐渐受到了广泛关注。
基于此,本文将系统性地回顾视频语义编码领域的最新研究成果,重点梳理现有方法的优势与不足,并探讨未来的研究方向。本文提出了一种新的分类视角,即按照与传统编码技术的兼容性将现有方法分为两类:深度学习驱动的编码框架和传统与智能协同编码框架。首先,介绍了深度学习驱动的编码框架,涵盖特征流编码、视频流编码和人机协同编码三种技术路线。这类方法完全基于神经网络,通过端到端训练能够显著提升系统性能,但在实际应用中,往往面临着较高的计算开销和复杂的训练过程等挑战。其次,探讨了传统与智能协同编码框架,该框架巧妙地将传统视频编码技术与AI结合,提升了系统的整体性能和适应性。最后,总结了视频语义编码面临的主要挑战,并展望了未来的研究方向,例如在提升系统泛化能力、降低计算复杂度、标准化等方面的潜在研究重点。
1 深度学习驱动的编码框架
传统视频压缩方法,无论是经典的编码标准[14-16],还是基于深度学习的模型[17-19],通常将提升视频的重建质量作为主要目标,但往往未能充分考虑视频理解任务对语义信息的迫切需求。与传统的面向人眼视觉的压缩方法不同,视频语义编码更加关注如何保留视频中的关键语义特征,以支持下游智能分析任务。
为了实现这一目标,通常利用深度学习模型的强大学习能力,构建完全基于神经网络的端到端框架,从原始视频中自动提取高层次的语义特征。本文称之为深度学习驱动的编码框架,这类框架能够自适应地学习视频数据中的复杂特性,生成紧凑的语义表示。具体而言,根据实现方式的不同,该框架的技术路线包括特征流编码、视频流编码以及人机协同的可伸缩编码,如图1所示:
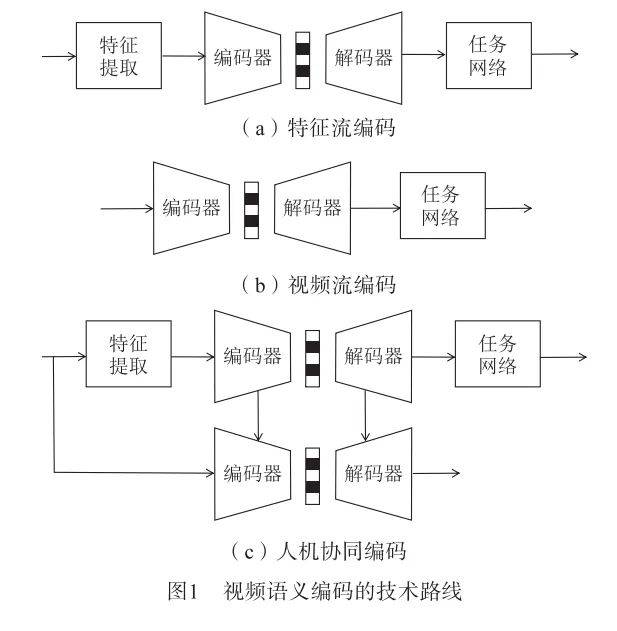
1.1 特征流编码
在路线1中,原始视频首先经过特征提取器提取出能够表征下游视觉任务的语义特征,然后进行压缩和传输,最后使用重构的语义特征执行下游机器视觉任务。例如,文献[20]通过端到端联合优化压缩特征的码率和分类任务的损失以学习更有效的特征。Chen等人[21]使用预训练的卷积神经网络提取从原始图像中提取具有高泛化能力的中间层特征进行传输,接收端只需要结合浅层的任务特定模型进行视觉分析。Feng等人[22]通过自监督对比学习从原始图像中提取紧凑通用的全能特征,随后通过信息过滤模块去除与下游任务关联较弱的冗余信息。经过过滤后的语义信息再由特征压缩器进行压缩,最终部署到检测、分割和姿态估计等不同任务中。文献[23]提出一种端到端可学习的多尺度特征压缩方法,首先对较大尺度的特征进行编码,然后逐步融合较小尺度特征,将特征融合与编码过程交替进行,最终对所得的特征进行熵编码并传输。
特征流编码通过仅压缩传输必要特征减少数据量,降低带宽和存储需求,但不足在于无法重构原始信号且性能高度依赖于特征提取器的质量,限制了其在需要原始信号的场景下的应用。
1.2 视频流编码
这类方法通常采用端到端压缩框架,通过在损失函数中加入任务特定的损失项以提高特定任务的性能。然而,如何增强解码比特流在不同视觉任务上的泛化能力,以支持多种下游任务,仍有待进一步探索。
1.3 人机协同编码
这类方法的优点在于能够同时满足人类视觉观感和机器分析的需求,但在保证性能的前提下,如何消除不同层之间的信息冗余以进一步节省码率,依然是一个难以解决的问题。
2 传统与智能协同编码框架
基于深度学习的视频语义编码研究已提出多种解决方案,通常依赖于基于学习的图像或视频编解码技术,通过端到端优化提升压缩效果。然而,这些方法在实际部署时仍需克服一系列挑战,包括计算复杂度高、标准化进程尚处于早期阶段,以及在实现落地过程中可能面临的诸多难题。相比之下,传统编码算法因技术成熟、稳定性高,已被广泛应用。在此背景下,自然而然提出了一个关键问题:“传统视频压缩编码是否可以向视频语义编码平滑过渡,像素级信息与语义级信息是否可以协同编码”,针对这一问题,已有一些探索性工作可以分为两个方向:一是通过预处理增强的语义编码,即在编码前去除图像或视频中与下游任务无关的内容,以节省传输带宽;二是特征流辅助的语义编码,即通过在编码过程中增加辅助特征流来提升下游任务性能。 表1提供了不同方案的简要概述。
2.1 预处理增强的语义编码
Lu等人提出了一种基于传统编解码器的语义增强图像压缩框架[33],在保持与传统标准兼容性的基础上,通过在传统编码传输链路前引入神经网络前处理模块,对输入图像进行基于AI的过滤增强,保留与机器任务相关的语义信息并抑制无关内容,从而降低比特率。前处理模块采用双分支架构,其中一支基于1×1卷积实现像素级非线性变换,用于保留浅层纹理信息,另一支采用U-Net结构提取深层语义特征,最终两个分支的输出叠加生成语义增强后的图像。此外,为应对传统编码器不同量化参数的影响,前处理模块集成了量化自适应层,能够根据量化参数动态调整中间特征,实现自适应优化,使其在压缩率和分析任务性能之间取得更优的平衡。
2.2 特征流辅助的语义编码
(1)基于对比学习的压缩视频理解
(2)基于掩码图像学习的压缩视频理解
文献[35]提出了一种基于自监督学习的视频语义压缩框架,旨在提升视频解码后的语义完整性。在编码端,语义提取网络用于提取原始视频与压缩后有损视频的语义特征。接着,通过自编码器网络压缩原始视频与有损视频之间的语义残差。与传统方法不同,该方法不仅传输视频的压缩信息,还传输在压缩过程中丢失的语义残差信息。在解码端,语义视觉信息融合网络将语义信息与有损视频融合,补偿丢失的语义特征,从而生成高质量的解码视频。此外,整个网络采用掩码图像学习[36]的方式进行优化,并引入基于高斯混合模型的非语义信息抑制策略,通过将视频语义特征建模为条件化高斯混合模型,在重建时显式降低非语义信息的熵,从而减少冗余信息的编码。
Tian等人在文献[35]的基础上进行了改进和扩展,文献[37]主要通过引入掩码运动预测目标来增强视频时间语义的学习,采用基于Transformer的压缩模块提高语义压缩的效率,从而更有效地捕捉和压缩视频内容的语义信息,在多个视频分析任务和数据集上展现出了更优的性能。
3 开放性问题
在视频语义编码的研究和应用中,尽管已经取得了一些进展,但仍然面临诸多挑战。这些挑战不仅涉及技术层面的复杂性,还涉及到实际部署和应用中的种种困难。
3.1 多任务泛化能力
3.2 计算复杂度与资源需求
基于AI的语义编码方法在性能上展现了巨大的潜力,但它们通常伴随高昂的计算开销。以JPEG-AI为例[38],在其压缩效率相对H.266能提升27%的情况下,解码一个像素所需的乘法累加器计数约为215千次,CPU解码时间是H.266的29倍。这表明,基于学习的视频编码器的性能优势往往以更高的计算复杂度为代价。因此在实际部署中,功耗和实时处理能力仍然面临巨大挑战,这也限制了其在低功耗和移动端设备上的应用。
3.3 自监督学习的挑战
尽管一些研究提出通过自监督学习方案[22, 34-35, 37]来减少对人工标注数据的依赖,并提高模型的普适性,但现有的自监督学习方法在优化目标上仍不明确。自监督学习模型的决策过程通常缺乏透明度和可解释性,增加了模型的复杂性。此外,尽管自监督学习依赖于大规模无标签数据,但如何从这些数据中有效提取有意义的特征,并确保训练过程的稳定性和收敛性,依然是一个复杂的问题。
3.4 标准化的挑战
目前,视频语义编码的相关标准尚未明确,大多数AI编码器的设计和训练流程缺乏统一的规范,导致不同团队提出的解决方案各不相同,这在一定程度上阻碍了技术的推广和标准化进程。在AI技术迅速发展的背景下,如何制定既具有适应性又可持续的标准,以确保未来AI视频编码技术的兼容性和广泛应用,成为亟待解决的问题。例如,是否应该统一训练流程,或统一权重的定义,都是需要讨论的问题。
3.5 AI与传统技术的融合
尽管AI技术在图像编码领域的应用已经取得显著进展,尤其是在视频语义编码的研究中,许多方法尝试用AI替代传统的视频编码技术。然而,实际应用场景中,AI与传统技术的融合仍面临许多挑战。具体来说,AI和传统编码方法的融合,能否实现全盘替换,还是将AI技术与现有的编码技术进行融合升级,这一问题仍需进一步探索。在实际部署中,如何平衡两者的优缺点,提高系统的可扩展性和适应性,仍然是技术发展的关键。
4 结束语
视频语义编码作为语义通信的重要组成部分,近年来得到了广泛的关注与研究。随着深度学习技术的发展,视频语义编码框架逐步向智能化、高效化的方向发展。本文回顾了该领域的研究进展,重点分析了深度学习驱动的编码框架和传统与智能协同编码框架,并探讨了其优势与局限。尽管取得了显著进展,但视频语义编码仍面临多任务泛化能力差、计算复杂度高、标准化缺乏等一系列挑战。
未来的研究需要在多个方向深入探索。首先,为提升多任务泛化能力,应开发更通用和灵活的模型,以便在不同任务间共享知识并优化整体性能。其次,降低计算复杂度和资源需求将是实现视频语义编码广泛应用的关键,未来的研究可集中在设计高效的网络架构和模型轻量化方法,从而实现更低功耗和更高的实时处理能力。此外,还需明确自监督学习的优化目标,提升模型可解释性;在标准化方面,制定统一标准和确保兼容性至关重要;AI与传统通信系统的融合也需进一步探索。
随着6G、自动驾驶、具身智能等领域需求的持续增长,视频语义编码将在提升效率和系统适应性方面发挥关键作用,未来有望实现更多技术突破,并推动其在实际应用中的广泛普及。
参考文献:(上下滑动浏览)
[1] Qin Z, Tao X, Lu J, et al. Semantic communications: Principles and challenges[EB/OL]. (2022-6-27)[2024-11-11]. https://arxiv.org/pdf/2201.01389.
[6] Huang D, Tao X, Gao F, et al. Deep learning-based image semantic coding for semantic communications[C]//2021 IEEE Global Communications Conference (GLOBECOM). IEEE, 2021: 1-6.
[8] Liu S, Li N, Deng Y. Goal-Oriented Semantic Communication for Wireless Visual Question Answering with Scene Graphs[EB/OL]. (2024-11-3)[2024-11-11]. https://arxiv.org/pdf/2411.02452.
[9] Yang K, Wang S, Dai J, et al. WITT: A wireless image transmission transformer for semantic communications[C]//ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023: 1-5.
[11] Wang S, Dai J, Liang Z, et al. Wireless deep video semantic transmission[J]. IEEE Journal on Selected Areas in Communications, 2022,41(1): 214-229.
[12] Qin Z, Liang L, Wang Z, et al. AI empowered wireless communications: From bits to semantics[J]. Proceedings of the IEEE, 2024.
[14] Wiegand T, Sullivan G J, Bjontegaard G, et al. Overview of the H. 264/AVC video coding standard[J]. IEEE Transactions on circuits and systems for video technology, 2003,13(7): 560-576.
[15] Sullivan G J, Ohm J R, Han W J, et al. Overview of the high efficiency video coding (HEVC) standard[J]. IEEE Transactions on circuits and systems for video technology, 2012,22(12): 1649-1668.